System Design - Databases, data models and indexing
December 23, 2025 |
system-design,
databases
- Related pages
Database#
What they are#
- Abstracted organization of data
- Software layer between the client and the storage
- Considerations in a distributed system
- Replication, Geo-Distribution and consistency
- Implements some of the BASE and/or ACID models
- Additional complexity due to architectural decisions
- Different types of databases
- Databases NewSQL
- Non-relational databases
- Relational databases
- Timeseries databases
- Memory databases
Relational Databases (SQL)#
- Tables, Tuples and columns
- Rigid and declarative schema
- We define all restrictions, types, cohesion rules, foreign key constraints, etc.
- Column id(int) does not allow a string, for example
- Strong consistency
- ACID
- Strong reference integrity
- Transaction model
- Focuses on integrity and durability
- Attributes that they can relate to each other (FKs, etc)
- Examples are:
- PostgreSQL
- MySQL / MariaDB
- Oracle
- SQLServer
- Etc.
Non Relational Databases (NoSQL)#
- Flexible schemas
- Eventual consistency
- Different data formats
- Documents, key-value, graphs, column
- Optimized horizontal scaling
- Generally higher write performance, geo distribution, etc. (in exchange of not so much consistency)
- No guarantee of integrity and atomicity
- Data semi-structured
- Examples are:
- MongoDB
- MemcachedDB
- Cassandra
- Redis
- Elasticsearch
- Etc.
- One of the characteristics is to prevent costly joins
- Non relational = not relation between the data
- For example, in MongoDB, we can have relationship between the collections, but it is not recommended, given we have to make many queries to relate them
- If we need to relate entities, use a related database
NewSQL Databases#
- ACID + Horizontal scalability
- Sharding and replication
- RAFT/Paxos
- New proposal that focuses on resolving the trade-offs of SQL and NoSQL regarding strong consistency, performance and horizontal scalability
- Seek to provide some reliability in terms of transactions
- Not yet super mature
- Examples are:
- CockroachDB
- Google Cloud Spanner
- MemSQL
- VoltDB
- AltiBase
In-Memory Database#
- Uses volatile memory – non-persistent in disk
- Latency of nanoseconds in RAM
- Key-value model
- Non structured
- Volatile and performance
- Scales through consistent hash
- Layer of cache and intensive reads
- Data needs to be reconstructible
- Focuses on non-durable data
- Useful for data that doesn’t change much, caching, etc
- Trade-off of not having the most updated value
- Important data is generally not stored in these databases
- Examples are:
- MemcachedDB
- Redis
- Valkey
- Apache Ignite
- Aerospike
Time-Series Databases (TSDB)#
- Append Only
- Generally we do not update data
- Temporal indexing
- High ingestion
- Analytical queries
- Used in metrics and logs
- Automatic expurge
- Supports high load of write operations
- Mathematical operations
- Sequential and segmented based on the collection time
- Examples are:
- Timescale
- InfluxDB
- Prometheus
- VictoriaMetrics
- Graphite
- Grafana Mimir
Levels of consistency#
- When discussing distributed systems, the choice of level of consistency of data is an important factor
- Knowing when to choose eventual consistency or strong consistency can either elevate the scalability of the system, as well as generate scalability problems. Race-conditions problem, data loss, high-throughput reads/writes, data durability, etc.
- Strong consistency vs Eventual consistency
- Impact in client experience
- Reliability vs performance
- Integrity vs Scalability
- Levels of integrity
Strong consistency#
- Linearity
- Synchronous Quorum
- Paxos and Raft
- Write latency
- More reliability
- Atomicity and transactions
- Consistent state -> consistent state
- Flow of synchronous commits
- Critical and atomic operations
- Examples of databases are:
- MySQL
- MariaDB
- PostgreSQL
- Oracle
- Cassandra (requires configuration)
Eventual consistency#
- Asynchronous replication
- High availability
- Tolerance and partitions
- Strategies to resolve conflicts
- Last-Write-Wins, CRDT (Conflict-free Replicated Data Type)
- The last version of the data, is the one that stays (generally based on a timestamp)
- High throughput and low latency
- Requires time to reflect data in all nodes
- Examples are:
- ScyllaDB
- DynamoDB
- CouchDB
- MongoDB
- Elasticsearch
- Etc.
Data Models#
Tuple (Row-Oriented)#
- OLTP
- Row = tuple, where each item in the tuple corresponds to the column
- Cache of pages
- Page size
- Low latency per row
- Groups attributes of the same entity physically in the same block
- We join different tables to query a particular data
Documents#
- Flexible schemas
- Autonomous entities
- Not much rigid field verification
- JSON/BSON
- Inverted indexing
- Full-Text search
- Allows changing schema without complex migration
- No relationship such as Row-Oriented
- Normally, the JSON contains all the needed data (i.e. single schema)
- Examples of usage is to represent a product catalog, log aggregation, etc.
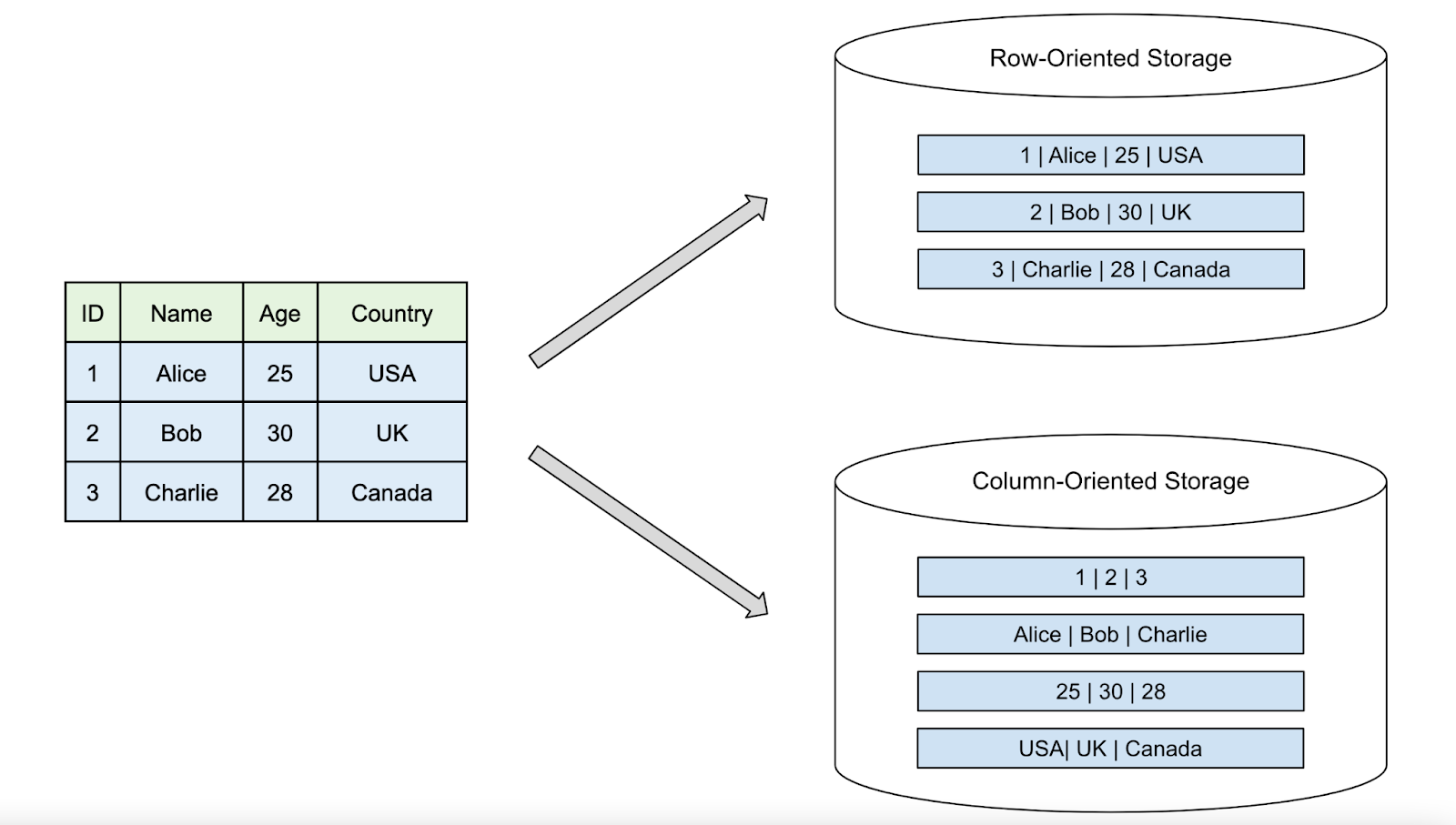
Column-Oriented#
- Contigous columns
- Instead of being row (such as SQL), where the whole row is stored in a
block, Column-Oriented is the same, but columns. So instead of a row such as
(Ben, 31, Amsterdam)being sequentially stored, just the column is stored near each other.
- Instead of being row (such as SQL), where the whole row is stored in a
block, Column-Oriented is the same, but columns. So instead of a row such as
- Compression
- Analytics, Big Data, Data Warehouse
- Helps analyse a large amount of the same data, such as optimized queries on top of the same attribute
- Heavy Scans of specific values
- Examples of such DB:
- ClickHouse
- Amazon Redshift
- Google BigQuery
- SnowFlake
- MariaDB ColumnStore
- Row-Oriented is useful when we need to retrieve the whole entity, and Column-Oriented is useful for when we need to perform analytical or math operation on top of the same attribute (column), regardless of the amount of rows we have.
Wide-Column#
- Family of column per row
- Flexible schema per row
- Each row can have its own set of columns
- Aggregated by family of column
- Efficient for data that varies
- Efficient for distributed data
- Eventual Consistency
- Supports atomicity and joins
- Examples:
- Cassandra
- ScyllaDB
- HBase
- DynamoDB
- CosmosDB
Key-Value#
- Direct lookup
- Parity hashing
- Key (unique identifier)
- Value (unstructured)
- Strings, numbers, booleans, JSON and Blobs
- Easy to query and indexing
- Examples:
- Redis
- Memcached
- Aerospike
- Etcd
- ZooKeeper
Graphs#
- Relationship of data is as important as the data itself
- Nodes (entity)
- Edges (relationship)
- Useful for recommendation feature
- Unstructured model
- Examples include:
- Neo4j
- CosmosDB
- OrientDB
- ArangoDB
- Neptune
DONE Indexing#
- The way the DB engine manages the storage and the indexing of that data, it impacts the performance
- Without indexing, even for a simple query, it would have to scan the whole database to find that data
- Indexing is how the DB stores and queries the data
- Concepts of: Page Size, Column Index, LSM-Tree, B-Tree, Hashing, Inverted Index
Page Size#
- Organized blocks of fixed size (4kb, 8kb, etc) – configurable
- If we store data, that is indexed by the date, we store each row sequentially in a page, until we reach that page limit, then we proceed to another page
- If we are indexing by date, these blocks will be stored near each other
- Block are rows (Tuple-Oriented) – Generally SQL databases
- Large pages: reduces read I/O operations in large objects
- If we have a large set of data, larger page sizes reduces the need of the engine having to open and close different pages to read the data
- Increase the cost of data transfer
- Bad for simple queries, as we need to open a large page to query something simple
- Smaller pages: Lower reads in irrelevant data on simple queries
- Increases I/O operations
- Minimizes opening large pages to query
- For example, if we need to aggregate a lot of data in a table, larger pages might be better, if our data has smaller entities, straightforward queries, smaller pages might be better
- Databases that uses page sizes are:
- MySQL
- PostgreSQL
- Oracle databases
- Apache Cassandra
Column-base Indexing#
- Contigous segments of columns
- Each column is stored in a segment
- Compressed through a lookup table
- High performance for aggregation
- Reduces I/O with compression
- Searches for specific attributes
- Analytics workflow
- Data compression is more efficient when we have less data diversity
- Examples are:
- Amazon Redshift
- BigQuery
- SnowFlake
- DuckDB
LSM-Trees (Log-Structured Merge-Tree)#
- Optimized for intensive write operations
- Low latency of ack
- Memtable (RAM) -> SSTables (Disk)
- Append-Only, Tomstones and compaction
- Sequential writes extremely fast – Fire and Forget
- Generally no in-place update
App makes a write request -> MemTable -> Flush to disk -> SSTables
Ideal for when you need to trace financial transactions, audit requirements, etc.
Example are:
- Cassandra
- Apache HBase
- Victoria Metrics
- Elasticsearch
Eventual consistency
B-Tree Indexing#
- Multi-Way balanced tree
- A node is stored in disk blocks
- Search, insertion and removal is of \(O(\log_n)\)
- Standard in SQL databases
- Disk access is optimized through minimum depth
- Range queries
- System only loads the disk blocks (pages) necessariry to iterate from the root node up until the key node
- Example DBs include PostgreSQL, SQL Server, MySQL, SQLite, etc.
Indexing through hashing#
- Exact-matches
- Direct and instant search
- Coalition is handled through chaining
- Hash bucket (i.e. Hashtable)
- Ideal for exact keys
- Examples include: PostgreSQL, Redis, Memcached, ValKey, MySQL, etc.
Inverted indexes#
- Standard tokens
- Full-text search
- Large-scale search of text types
- Allows searching for long text and values through simple terms
- Maps the term for the documents where they are located
- Examples include: ElasticSearch, MongoDB and Apache Lucene
Write-Intensive example#
Where there are more writes than read operation.
- We can use an append-only DB
- Asynchronous replication
- Eventual consistency
- LSM-Trees
- Write through memory
- Non-blocking disk
Read-Intensive example#
Where there are more read than write operation.
- Read replicas
- Cache layer
- CQRS for optimization
- Distributed read